One thing that always puzzled me, when I first started learning statistics, was the Chi-squared tests. Adding up rescaled squared differences of course gives us a distance measure, but why would the denominator be  ? After all, the variance of a binomial, for example, would be
? After all, the variance of a binomial, for example, would be
 = E(1-p)") ,
,
so for this to be Chi-squared distributed, should we not be dividing by ") ? And, if so, is our
? And, if so, is our  statistic not out by a factor of
statistic not out by a factor of ") ? Which, for any reasonable-sized
? Which, for any reasonable-sized  , could be quite a huge discrepancy.
, could be quite a huge discrepancy.
The web turned out to be full of nasty red herrings trying to fool me into the wrong conclusion. I trawled through pages that claim we have a Poisson distributon when we don’t (and which have no way of justifying the degrees of freedom we are using), and pages that admit that their derivations are out by but simply suggest that it’s “preferable to omit the factors (1 – pi) in the denominators” (!).
It’s all in the covariance matrix
Eventually, I found some good resources, and the way it works is really surprisingly nifty! I have detailed some good and bad derivations, along with my own more concise version of the good derivations here, but all you really need to know is that the covariance matrix of your  terms looks like this:
terms looks like this:
 ,
,
where elements of the (notation-abusing) vector  are the square roots of the probabilities
are the square roots of the probabilities  of each respective outcome in the multinomial model that we are modelling. I should, of course, stress that the goodness-of-fit test is a model designed for testing multinomial outcomes, and should not be confused with other countable outcomes, for which similar, but subtly different tests can sometimes be derived. Crucially, note that
of each respective outcome in the multinomial model that we are modelling. I should, of course, stress that the goodness-of-fit test is a model designed for testing multinomial outcomes, and should not be confused with other countable outcomes, for which similar, but subtly different tests can sometimes be derived. Crucially, note that  is a unit vector (since the probabilities must all sum to one).
is a unit vector (since the probabilities must all sum to one).
What does this covariance matrix tell me?
If you’re super happy with linear algebra and covariance matrices, you can skip to the next subsection. If you’re new to linear algebra (the vectors and matrices I’ve used above), I’ll show you a diagram of it in a minute, and underneath the first diagram is a simpler summary. If you have studied some basic linear algebra, but are not sure how to understand this matrix, think of it this way.
This matrix tells us how much variance we have in any given direction; to find out how much variance we have in a given direction, try multiplying a vector that points in that direction, and see how it gets stretched. For example, if I multiply the vector into this matrix, I will get a vector full of zeros as a result (bear in mind that is a unit vector, so  ). So, we can see that in the direction , our vector gets multiplied by zero, and there is zero variance.
). So, we can see that in the direction , our vector gets multiplied by zero, and there is zero variance.
Now, imagine we multiplied a new vector  into this matrix that is orthogonal to (that is,
into this matrix that is orthogonal to (that is,  ). Then the second term in the covariance matrix will give us zeros, and the matrix acts like the identity matrix: that is, our vector gets stretched by a factor of
). Then the second term in the covariance matrix will give us zeros, and the matrix acts like the identity matrix: that is, our vector gets stretched by a factor of  (i.e. not at all!). And the variance in every direction that is orthogonal to is . Furthermore, since it acts as the identity matrix in these orthogonal directions, there is no correlation in the distributions along these vectors.
(i.e. not at all!). And the variance in every direction that is orthogonal to is . Furthermore, since it acts as the identity matrix in these orthogonal directions, there is no correlation in the distributions along these vectors.
So, why is this Chi-squared distributed?
So, our covariance matrix explains everything!! If our count table has  elements, then we have one direction () that has zero variance (effectively does not exist), and
elements, then we have one direction () that has zero variance (effectively does not exist), and ") orthogonal directions in which we have the variance we wanted of , and zero covariance with each other. To visualize this, we have a unit sphere that has been squashed flat in the direction . When we add up our correlated, non-unit-variance, squared distances
orthogonal directions in which we have the variance we wanted of , and zero covariance with each other. To visualize this, we have a unit sphere that has been squashed flat in the direction . When we add up our correlated, non-unit-variance, squared distances ^2}{e_i}") , we end up with the same squared distance as if we had added up the uncorrelated, unit-variance squared distances orthogonal to .
, we end up with the same squared distance as if we had added up the uncorrelated, unit-variance squared distances orthogonal to .
Assuming that this distribution tends towards being multivariate normal (and central limit theorem gives us that it does), then this squared distance will be }") -distributed (based on the rotational symmetry of the normal distribution).
-distributed (based on the rotational symmetry of the normal distribution).
Visualising the covariance matrix
That is, to see that we have unit variance, we need to rotate our perspective to look along the direction of the vector , as illustrated in the figure below (which shows the distribution for a binomial with probability of success  ). Looking along the axes, for example, if we consider only the number of successes in the binomial case, and ignore the number of fails, we do have the wrong variance — but that is because we are looking at our distribution from the wrong angle. Aligning ourselves to look at 45 degrees (in this case, since
). Looking along the axes, for example, if we consider only the number of successes in the binomial case, and ignore the number of fails, we do have the wrong variance — but that is because we are looking at our distribution from the wrong angle. Aligning ourselves to look at 45 degrees (in this case, since =0.5") and
and  ), we are suddenly looking at a normal distribution with unit variance.
), we are suddenly looking at a normal distribution with unit variance.
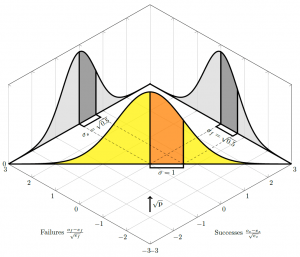
If you’re struggling to follow the technical lingo, think of the above diagrams this way. The total number of trials is fixed, so every extra success means one fewer fail. That is why our distribution cuts across the middle of the graph in a straight line; we can’t go anywhere but that line; gaining a success must lose us a fail. If we look at just the successes or the fails in isolation, we have a variance of ") , just as I was pondering at the top. But when we rotate ourselves to look at this line we are tracing between the two, we can see, just by a simple application of Pythagoras, that our two “wrong” normal distributions collapse into a single normal distribution that has variance of . Once we have normal distributions with unit variance, we can compare them against a distribution.
, just as I was pondering at the top. But when we rotate ourselves to look at this line we are tracing between the two, we can see, just by a simple application of Pythagoras, that our two “wrong” normal distributions collapse into a single normal distribution that has variance of . Once we have normal distributions with unit variance, we can compare them against a distribution.
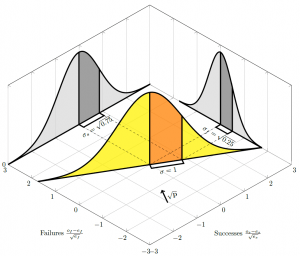
Changing the probability of success
As the probability of success decreases, rotates, and the proportion of variance contributed by each axis changes:
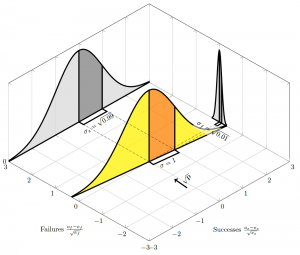
As ") gets closer and closer to zero, we get closer and closer to a Poisson, and (in this special case) the “Poisson” argument looks more credible; this can be seen as starts to align with the “failures” axis as
gets closer and closer to zero, we get closer and closer to a Poisson, and (in this special case) the “Poisson” argument looks more credible; this can be seen as starts to align with the “failures” axis as  \rightarrow 0") and the variance on the successes axis heads towards unity:
and the variance on the successes axis heads towards unity:
^2}{E}") because
because  to be the vector of
to be the vector of  to be the vector of expected values. In the goodness-of-fit test, we are modelling that the observed values are the counts from a multinomial distribution. So
to be the vector of expected values. In the goodness-of-fit test, we are modelling that the observed values are the counts from a multinomial distribution. So  = \mathbf{e}") , and the observed and expected values will sum to the same value (
, and the observed and expected values will sum to the same value ( ).
). ") . For this part, I will use the analogy and (similar notation) from the derivation
. For this part, I will use the analogy and (similar notation) from the derivation  balls
balls  into
into  , and our observed values
, and our observed values  are given by the number of balls in each given bucket:
are given by the number of balls in each given bucket:") .
.")
![= \mathbb{E}\left(\left[\sum\limits_{l=1}^n I(X_l \in B_i)\right]\left[\sum\limits_{l'=1}^n I(X_{l'} \in B_j)\right]\right)](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D%5Cleft%28%5Cleft%5B%5Csum%5Climits_%7Bl%3D1%7D%5En+I%28X_l+%5Cin+B_i%29%5Cright%5D%5Cleft%5B%5Csum%5Climits_%7Bl%27%3D1%7D%5En+I%28X_%7Bl%27%7D+%5Cin+B_j%29%5Cright%5D%5Cright%29&bg=ffffff&fg=000000&s=0 "= \mathbb{E}\left(\left[\sum\limits_{l=1}^n I(X_l \in B_i)\right]\left[\sum\limits_{l'=1}^n I(X_{l'} \in B_j)\right]\right)")
I(X_{l'} \in B_j)\right)")
I(X_{l'} \in B_j) + \sum_{l \neq l'} I(X_l \in B_i)I(X_{l'} \in B_j)\right)")
I(X_{l'} \in B_j)\right)}_{=I(i=j)p_i} + \sum_{l \neq l'} \underbrace{\mathbb{E}\left(I(X_l \in B_i)I(X_{l'} \in B_j)\right)}_{=p_ip_j}")
![= n \left[ I(i=j)p_i \right] + n(n-1) \left[ p_ip_j \right]](https://s0.wp.com/latex.php?latex=%3D+n+%5Cleft%5B+I%28i%3Dj%29p_i+%5Cright%5D+%2B+n%28n-1%29+%5Cleft%5B+p_ip_j+%5Cright%5D&bg=ffffff&fg=000000&s=0 "= n \left[ I(i=j)p_i \right] + n(n-1) \left[ p_ip_j \right]")
e_i + \frac{n-1}{n}e_ie_j") ,
, there is zero for
there is zero for  ).
). = \mathrm{diag}(\mathbf{e})+\frac{n-1}{n}\mathbf{ee}^T") ,
, to denote the placing of the elements of the vector onto the diagonal of an otherwise zero matrix.
to denote the placing of the elements of the vector onto the diagonal of an otherwise zero matrix. is pretty easy. Making use of the facts that
is pretty easy. Making use of the facts that =\mathbf{e}") and, therefore
and, therefore =\mathbf{0}") :
:")
(\mathbf{o}-\mathbf{e})^T")
 - \mathbb{E}(\mathbf{o})\mathbf{e}^T - \mathbf{e}\mathbb{E}(\mathbf{o})^T + \mathbf{ee}^T")
 - \mathbf{ee}^T")
![= \left[ \mathrm{diag}(\mathbf{e}) + \frac{n-1}{n}\mathbf{ee}^T \right] - \mathbf{ee}^T](https://s0.wp.com/latex.php?latex=%3D+%5Cleft%5B+%5Cmathrm%7Bdiag%7D%28%5Cmathbf%7Be%7D%29+%2B+%5Cfrac%7Bn-1%7D%7Bn%7D%5Cmathbf%7Bee%7D%5ET+%5Cright%5D+-+%5Cmathbf%7Bee%7D%5ET&bg=ffffff&fg=000000&s=0 "= \left[ \mathrm{diag}(\mathbf{e}) + \frac{n-1}{n}\mathbf{ee}^T \right] - \mathbf{ee}^T")
 -\frac{1}{n}\mathbf{ee}^T")
^2") . What happens when we divide by
. What happens when we divide by  ? Here, for succinctness, I will use the slight abuse of notation that
? Here, for succinctness, I will use the slight abuse of notation that  is calculated by taking the square root of each element of
is calculated by taking the square root of each element of ![\mathrm{cov} \left( \left[\mathrm{diag}(\sqrt{\mathbf{e}})\right]^{-1} (\mathbf{o}-\mathbf{e}) \right)](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bcov%7D+%5Cleft%28++%5Cleft%5B%5Cmathrm%7Bdiag%7D%28%5Csqrt%7B%5Cmathbf%7Be%7D%7D%29%5Cright%5D%5E%7B-1%7D+%28%5Cmathbf%7Bo%7D-%5Cmathbf%7Be%7D%29++%5Cright%29+&bg=ffffff&fg=000000&s=0 "\mathrm{cov} \left( \left[\mathrm{diag}(\sqrt{\mathbf{e}})\right]^{-1} (\mathbf{o}-\mathbf{e}) \right)")
![= \left[\mathrm{diag}(\sqrt{\mathbf{e}})\right]^{-1} \mathrm{cov} (\mathbf{o}-\mathbf{e}) \left[\mathrm{diag}(\sqrt{\mathbf{e}}) \right]^{-1}](https://s0.wp.com/latex.php?latex=%3D+%5Cleft%5B%5Cmathrm%7Bdiag%7D%28%5Csqrt%7B%5Cmathbf%7Be%7D%7D%29%5Cright%5D%5E%7B-1%7D+%5Cmathrm%7Bcov%7D+%28%5Cmathbf%7Bo%7D-%5Cmathbf%7Be%7D%29+%5Cleft%5B%5Cmathrm%7Bdiag%7D%28%5Csqrt%7B%5Cmathbf%7Be%7D%7D%29+%5Cright%5D%5E%7B-1%7D+&bg=ffffff&fg=000000&s=0 "= \left[\mathrm{diag}(\sqrt{\mathbf{e}})\right]^{-1} \mathrm{cov} (\mathbf{o}-\mathbf{e}) \left[\mathrm{diag}(\sqrt{\mathbf{e}}) \right]^{-1}")
![= \left[\mathrm{diag}(\sqrt{\mathbf{e}})\right]^{-1} \left( \mathrm{diag}(\mathbf{e}) -\frac{1}{n}\mathbf{ee}^T \right) \left[\mathrm{diag}(\sqrt{\mathbf{e}}) \right]^{-1}](https://s0.wp.com/latex.php?latex=%3D+%5Cleft%5B%5Cmathrm%7Bdiag%7D%28%5Csqrt%7B%5Cmathbf%7Be%7D%7D%29%5Cright%5D%5E%7B-1%7D+%5Cleft%28+%5Cmathrm%7Bdiag%7D%28%5Cmathbf%7Be%7D%29+-%5Cfrac%7B1%7D%7Bn%7D%5Cmathbf%7Bee%7D%5ET+%5Cright%29+%5Cleft%5B%5Cmathrm%7Bdiag%7D%28%5Csqrt%7B%5Cmathbf%7Be%7D%7D%29+%5Cright%5D%5E%7B-1%7D+&bg=ffffff&fg=000000&s=0 "= \left[\mathrm{diag}(\sqrt{\mathbf{e}})\right]^{-1} \left( \mathrm{diag}(\mathbf{e}) -\frac{1}{n}\mathbf{ee}^T \right) \left[\mathrm{diag}(\sqrt{\mathbf{e}}) \right]^{-1}")

